位置:首码圈项目网 > 首码发布
美国能强制收购DeepSeek吗?(请感受DeepSeek令人发狂的写作能力)
佚名 2025-01-29
本文全部由DeepSeek撰写,一笔未改。请感受DeepSeek令人发狂的写作能力。

“收购deepseek就像想买断长城,但砖石图纸早已散落人间。当中国把AI民主化进行到底时,硅谷的估值泡沫怕是连核电冷却塔都压不住了。”
要搞清楚美国能不能强买DeepSeek,得先看这家公司到底握着什么底牌。
先说最基本的法律层面,DeepSeek母公司幻方量化的股权结构就够美国人头疼的。
穿透到最上层,杭州余杭区政府产业基金占股21.5%,之江实验室占15.3%,中金资本占12.8%,这三家国资背景的股东合计持股接近五成。
去年新修订的《境外投资安全审查办法》里白纸黑字写着,人工智能核心算法和训练框架被列为"战略资产",任何涉及这些技术的跨境交易必须过G家网信办、发改委、商务部三道关卡。
更狠的是杭州市自己出的《数字经济保护条例》,直接把市级以上重点AI企业的数据资产和算法模型划成"非卖品",别说收购,连技术合作都要报备审批。
技术层面才是真正的杀手锏。DeepSeek最让硅谷睡不着觉的,是它把大模型的成本打到了地板价。
deepseekR12k布了预训练权重、训练细节、训练参数,什么意思?意思就是你按照人家发布的论文,有足够的算力,你就可以做一个出来,都不用花钱的,更谈不上强制出售。
他们自研的MoE架构(专家混合模型)有个绝活——动态激活技术。简单说就是每次推理只用12%的参数工作,剩下的88%躺平休息。
这招直接让1750亿参数的模型跑起来像840亿参数的轻量版,但效果却能对标GPT-3.5。更绝的是训练成本,256张A100显卡15天就能练出可用模型,这个配置在国内三十多个超算中心都能凑齐。
对比之下,OpenAI训练GPT-4用了10240张H100,光显卡成本就够买半个杭州未来科技城。
商业模式的颠覆更是一记重拳。当美国科技巨头们忙着抢核电站解决供电问题时,DeepSeek团队在论文里晒出了账单:用自研的"量子纠缠压缩算法",硬是把电力消耗砍掉57%。
去年谷歌为了训练Gemini模型,单次训练耗电量相当于旧金山全市三天的用电量,结果DeepSeek用不到600万美元就做出了性能相当的模型。这种成本差直接动摇了美国AI产业的根基——华尔街给OpenAI的估值是860亿美元,前提是他们能垄断高端大模型市场。
最后,deepseek免费、免费、免费!不管是使用,还是模型,都是开源免费的。deepseek给老美最大的伤害是,戳破了老美讲的小故事。
现在中国公司证明花小钱也能办大事,投资人开始集体质疑:凭什么要为美国公司的天价账单买单?
市场反应最能说明问题。英伟达H100的期货价格三周跌了18%,Anthropic最新融资估值被砍掉120亿美元,连马斯克都紧急叫停xAI的200亿美元募资计划。
这背后的逻辑很直白:当中国能用白菜价造出高性能AI时,美国那套"算力霸权"的故事就讲不下去了。更让白宫焦虑的是产业落地速度,比亚迪用DeepSeek做汽车质检系统,良品率提升了2.3%;海尔把它塞进冰箱生产线,每年省下8000万人工复检成本。这些数字砸在美股投资人脸上,比什么政治口号都管用。
美国不是没想过技术封锁,但现实很骨感。DeepSeek全套工具链都是开源架构,论文里连超参数调节技巧都写得明明白白。
就算美国人拿到代码,也复制不出中国特供版的产业生态——G家电网给AI企业开绿电特惠价,合肥智能算力中心提供白菜价GPU租赁,工信部直接补贴60%硬件成本。
这种举国体制的打法,硅谷那帮VC(风险投资)根本玩不起。就像当年高铁技术,图纸给你都造不出来,因为背后站着整个中国的产业链。
最讽刺的是技术反超路径。OpenAI还在死磕万亿参数模型时,DeepSeek走了条"小而美"的路线。他们的7B参数模型(70亿参数)通过动态稀疏化,实际效果吊打Meta的650亿参数Llama2。
这背后是算法层面的降维打击:用更聪明的架构设计代替无脑堆算力。现在连英国《经济学人》都承认,中国AI正在改写游戏规则——当美国公司花18亿美元买2.7万张H100显卡时,深圳五个95后程序员用开源的DeepSeek工具包,三天就做出了能写粤语RAP的AI应用。这种全民参与的创新生态,才是硅谷最害怕的"技术人民战争"。
所以回到最初的问题,美国能不能强买DeepSeek?答案早就藏在杭州西溪湿地边上那栋玻璃大楼里。
当中国把AI变成水电煤一样的基础设施,当每个大学生都能用开源工具训练自己的模型时,所谓的"强制收购"就成了个伪命题——就像没人能收购空气,因为技术民主化的浪潮早已渗透到每个字节。

扫码进群
标签:DeepSeek
相关推荐

DeepSeek官网下载安装,手把手教你轻松获取!

浅谈deepSeek的爆火现象以及如何看待中美之间AI领域之间的博弈关系

美国对DeepSeek下手!刚夸完就称是“偷窃”
揭秘!用这种方式打开Deepseek,远超99%的人!
HOT买手妈妈没有邀请码怎么注册?买手妈妈邀请码2918606

买手妈妈是什么平台?买手妈妈是一款由郑州买手妈妈科技有限公司开发的综合性导购分享平台,主要功能是提供海...
买手妈妈1个月前2.2w#买手妈妈
HOT趣闲赚:手机悬赏任务与游戏试玩,轻松赚取零花钱!

在移动互联网时代,越来越多的人希望通过手机兼职赚钱。悬赏任务和游戏试玩平台成为了热门选择,只需动动手指...
zyp12310天前1.73k#趣闲赚
易云甄选改名为(德孝泉),修改了原有制度!如果会员不兑单的情况下!2天都撑不住!
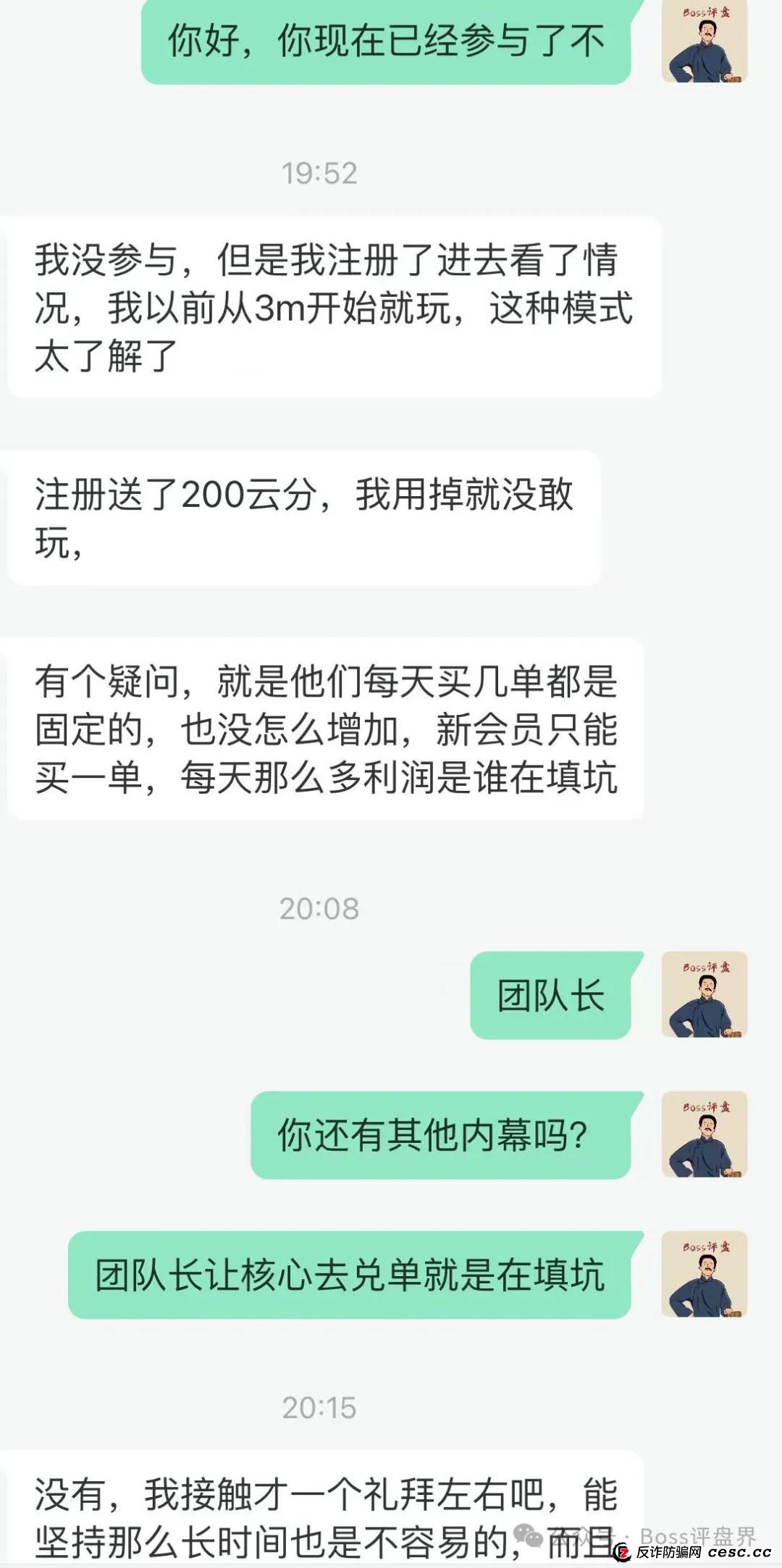
小编得到的最新的信息,易云甄选互助这个项目已经改名为德孝泉了!你们改名也消除不掉易云甄选整个盘面的大泡...
兼职招聘怎么看?大学生兼职哪里找?4大平台帮你轻松搞定

在如今多元化的社会环境下,越来越多的人希望通过兼职工作增加收入,这样可以积累经验或丰富生活。然而,如何...
加载中昨天294
DGCX鑫慷嘉大数据骗局深度解析:披着石油外衣的虚拟币杀猪盘

DGCX鑫慷嘉大数据骗局解析 高回报背后的陷阱 近期多地官方发布风险预警的DGCX平台,打着中国石油合作方旗号,用月...
警惕新型金融骗局:HKEX煜志金融资金盘陷阱深度解析

高收益承诺背后的庞氏骗局本质 近期,一款名为HKEX煜志金融的投资平台在社交媒体上引发关注,其宣称通过香港交易...
CAD 代画图兼职哪里找?如何开拓多元途径?看这篇就懂了

在当下充满机遇的就业环境里,兼职工作成为人们增加收入、提升技能的热门之选。而 CAD 代画图兼职,也吸引着大量...
佚名昨天159
2025年宠物上门喂养兼职平台有哪些?不容错过的5大兼职平台

随着宠物经济的蓬勃发展,越来越多的宠物主人开始寻求专业的上门喂养服务,以确保他们在忙碌或外出时,宠物能...
加载中昨天432
时光大掌柜:零成本轻松赚米,稳定项目无压力!
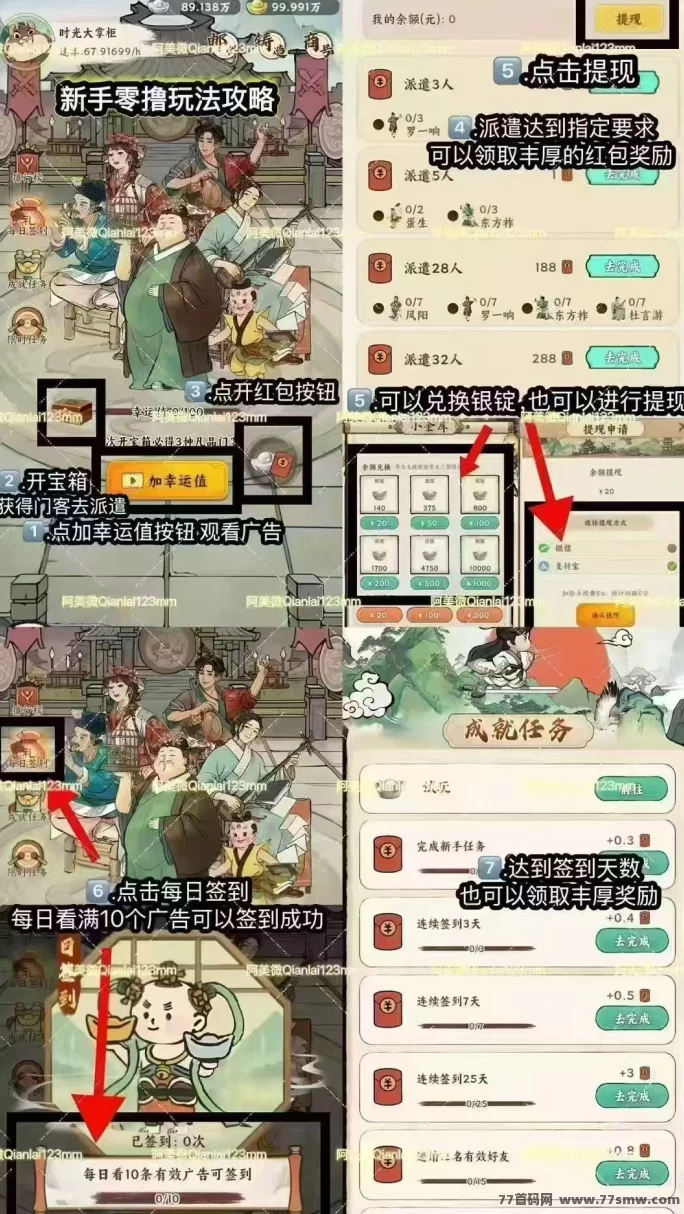
时光大掌柜是一款零投入、稳定回报的游戏项目,你可以通过简単的日常操作来获得奖励,轻松实现赚取收溢的目标...
首码项目1昨天307
蜂小推,简单推广赚收溢,让网磐变现更轻松!

如果你对网磐推广感兴趣,蜂小推是一个不容错过的优质平台!蜂小推专注于网磐推广,涵盖短剧、小说以及网磐资...
jbtfjbtfc昨天142
屠龙圣域首码上线,超高收溢等你来拿!

屠龙圣域全新首码正式上线,带给玩家们前所未有的收溢体验!这款传奇打金手游,不仅简単易上手,还能让你在游...
繁华如昔昨天202
猎人来了:零投入,稳定收溢,简单轻松赚!
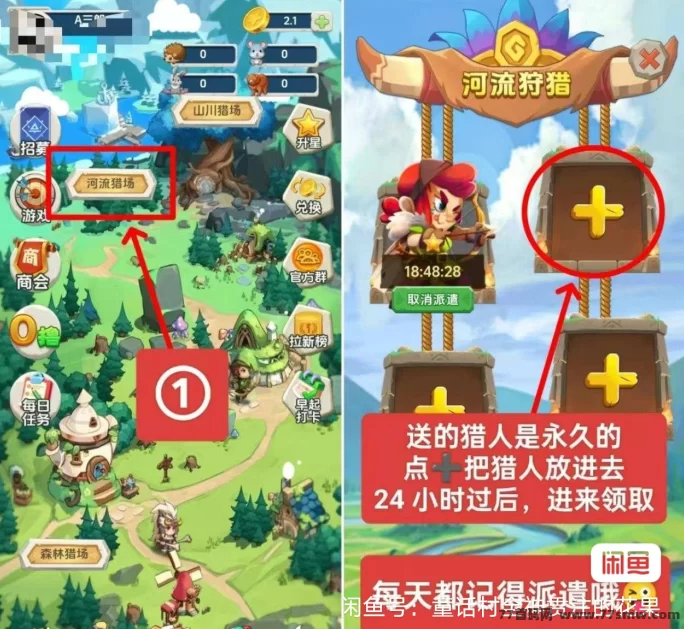
猎人来了是一款无需广告、零撸即可赚取金b的游戏,玩家通过简単的操作就可以稳定获得收溢!每位玩家都可以轻松...
首码项目1昨天187